Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
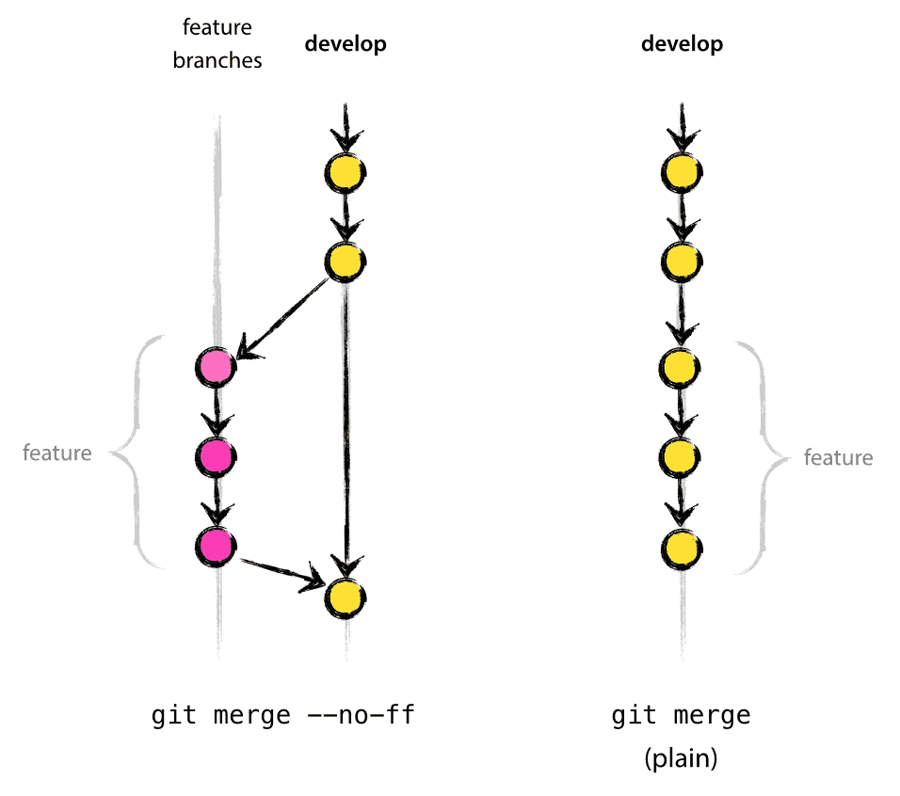
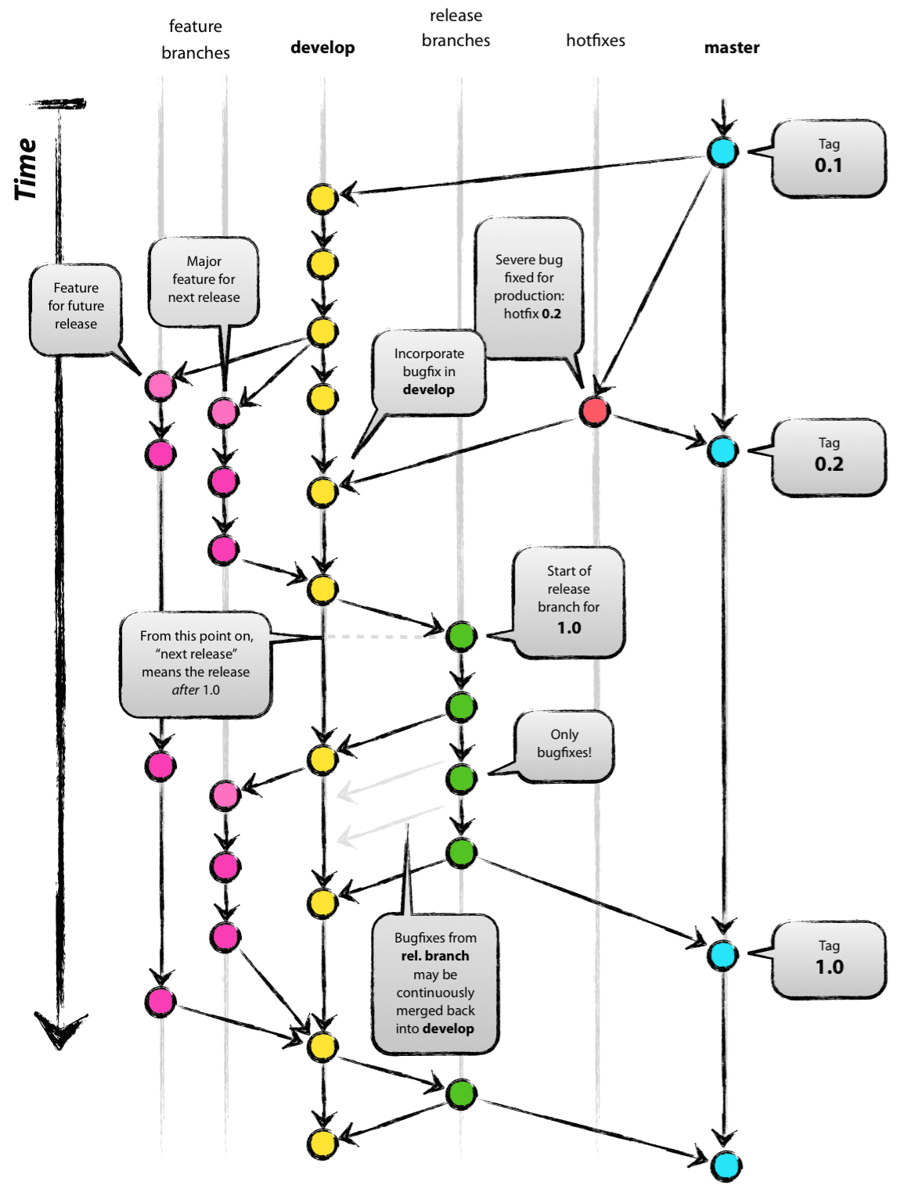
The general approach to branching used within the organisation.
git clone [email protected]:daritelska-platforma/frontend.git
cd frontend
# Symlink dev environment
ln -s .env.example .env
# Install dependencies
yarnyarn builddocker build . \
--file ./Dockerfile \
--target production \
--build-arg NODE_ENV=productionyarn devdocker-compose updocker-compose up -d
docker-compose logs -fyarn lint
yarn lint:styles
yarn format
yarn type-check## General ##
#############
COMPOSE_PROJECT_NAME=podkrepi
NODE_ENV=development # development, production
TARGET_ENV=development # development, production
## API ##
#########
API_URL=https://api.podkrepi.localhost/
## APP ##
#########
APP_URL=http://localhost:3040
APP_PORT=3040
## Next Auth ##
#############
NEXTAUTH_URL=https://http://localhost:3040
JWT_SECRET=!Change__Me!
## Discord ##
#############
DISCORD_CLIENT_ID=
DISCORD_CLIENT_SECRET=[
{
"id": "
{
"error": "Not Found"
{
"id": "5572f770-a434-4ed8-9a91-d94474d26c8e"
"name": "Campaign name"
}{
"error": "Not Found"
}@all-contributors please add @<username> for <contributions>import React from 'react'
import * as yup from 'yup'
import { useTranslation } from 'next-i18next'
import { Grid, TextField, Button } from '@material-ui/core'
import { AlertStore } from 'stores/AlertStore'
import useForm, { translateError, customValidators } from 'common/form/useForm'
export type FormData = {
email: string
}
const validationSchema: yup.SchemaOf<FormData> = yup.object().defined().shape({
email: yup.string().email().required(),
})
const defaults: FormData = {
email: '',
}
export type MyFormProps = { initialValues?: FormData }
export default function MyForm({ initialValues = defaults }: MyFormProps) {
const { t } = useTranslation()
const { formik } = useForm({
initialValues,
validationSchema,
onSubmit: (values) => {
console.log(values)
},
})
return (
<form onSubmit={formik.handleSubmit}>
<Grid container spacing={3}>
<Grid item xs={12}>
<TextField
type="text"
fullWidth
label={t('auth:fields.email')}
name="email"
size="small"
variant="outlined"
autoFocus
error={Boolean(formik.errors.email)}
helperText={translateError(formik.errors.email)}
value={formik.values.email}
onBlur={formik.handleBlur}
onChange={formik.handleChange}
/>
</Grid>
<Grid item xs={12}>
<Button fullWidth type="submit" color="primary" variant="contained">
{t('auth:cta.login')}
</Button>
</Grid>
</Grid>
</form>
)
}<MyForm />
<MyForm initailValues={{email: '[email protected]'}} />{
"invalid": "Field is invalid",
"required": "Required field"
}setLocale({
mixed: {
default: 'validation:invalid',
required: 'validation:required',
},
string: {
email: 'validation:email',
},
}){
"field-too-short": "Field should be at least {{min}} symbols",
"field-too-long": "Field should be maximum {{max}} symbols"
}setLocale({
string: {
min: ({ min }: { min: number }) => ({
key: 'validation:field-too-short',
values: { min },
}),
max: ({ max }: { max: number }) => ({
key: 'validation:field-too-long',
values: { max },
}),
},
})yup.string().min(6 customValidators.passwordMin)const validationSchema: yup.SchemaOf<FormData> = yup
.object()
.defined()
.shape({
password: yup.string().min(6, ({ min }) => ({
key: 'validation:password-min',
values: { min },
})),
}){
"cta": {
"login": "Log In",
"register": "Register",
"send": "Send",
"reset": "Reset"
},
"fields": {
"email": "Email",
"password": "Password",
"confirm-password": "Confirm Password",
"first-name": "First name",
"last-name": "Last name"
},
"pages": {
"forgotten-password": {
"instructions": "To reset your password, please type your email address below.",
"greeting": "Hello {{name}}!"
}
}
}import { useTranslation } from 'next-i18next'
export default function CustomComponent() {
const { t } = uxseTranslation()
return (
<div>
<h1>{t('nav.custom-page')}</h1>
<h2>{t('auth:pages.forgotten-password.greeting', { name: 'Interpolation' })}</h2>
<p>{t('auth:pages.forgotten-password.instructions')}</p>
</div>
)
}import { GetStaticProps } from 'next'
import { serverSideTranslations } from 'next-i18next/serverSideTranslations'
import Page from 'components/forgottenPassword/ForgottenPasswordPage'
export const getStaticProps: GetStaticProps = async ({ locale }) => ({
props: {
...(await serverSideTranslations(locale ?? 'bg', ['common', 'auth'])), // List used namespaces
},
})
export default Pagecd podkrepi.bg/frontend
kubectl apply -k manifests/overlays/developmentcd podkrepi.bg/frontend
kubectl apply -k manifests/overlays/productioncd podkrepi.bg/frontend
kubectl apply -k manifests/overlays/productioncd podkrepi.bg/backend
kubectl apply -k manifests/overlays/developmentcd podkrepi.bg/backend
kubectl apply -k manifests/overlays/productioncd podkrepi.bg/backend
kubectl apply -k manifests/overlays/productionimages:
- name: ghcr.io/podkrepi-bg/api/migrations
newTag: v0.3.3
- name: ghcr.io/podkrepi-bg/api
newTag: v0.3.3{
"id": "112cb853-b0b9-482e-a944-cf4fca5566b7",
"firstName": "John",
"lastName": "Doe",
"email": "[email protected]",
"company": "Camplight",
"phone": "+359888888888",
"message": "I wanna help",
"createdAt": "2021-03-19T00:36:50.076597738Z",
"updatedAt": "2021-03-19T00:36:50.076597738Z",
"deletedAt": null
}{
"statusCode": 400,
"error": "email: non zero value required;firstName: non zero value required;lastName: non zero value required;message: non zero value required;phone: non zero value required",
"validation": [
{
"field": "firstName",
"message": "firstName: non zero value required",
"validator": "required",
"customMessage": false
},
{
"field": "lastName",
"message": "lastName: non zero value required",
"validator": "required",
"customMessage": false
},
{
"field": "email",
"message": "email: non zero value required",
"validator": "required",
"customMessage": false
},
{
"field": "phone",
"message": "phone: non zero value required",
"validator": "required",
"customMessage": false
},
{
"field": "message",
"message": "message: non zero value required",
"validator": "required",
"customMessage": false
}
]
}[
{
"id": "0d6ff16e-ae4c-48e4-868c-05095d923053",
"firstName": "John",
"lastName": "Doe",
"email": "[email protected]",
"company": "Camplight",
"phone": "",
"message": "I wanna help",
"createdAt": "2021-03-19T00:11:21.031966Z",
"updatedAt": "2021-03-19T00:11:21.031966Z",
"deletedAt": null
},
{
"id": "76e6e2f7-b3f2-4df4-9185-cc44185e7c86",
"firstName": "John",
"lastName": "Doe",
"email": "[email protected]",
"company": "ACME",
"phone": "+359888888888",
"message": "I wanna help",
"createdAt": "2021-03-19T00:20:31.355736Z",
"updatedAt": "2021-03-19T00:20:31.355736Z",
"deletedAt": null
}
]{
"id": "112cb853-b0b9-482e-a944-cf4fca5566b7",
"firstName": "John",
"lastName": "Doe",
"email": "[email protected]",
"company": "Camplight",
"phone": "+359888888888",
"message": "I wanna help",
"createdAt": "2021-03-19T00:36:50.076597738Z",
"updatedAt": "2021-03-19T00:36:50.076597738Z",
"deletedAt": null
}{
"error": "No contact found",
"status": 404
}{
"status": 200
}{
"status": 404
}{
"id": "d1451c92-0e86-463a-bf1c-2e4554a77f30",
"person": {
"email": "[email protected]",
"name": "John Doe",
"phone": "+3598777777777",
"address": "6 John Doe Str",
"terms": true,
"newsletter": true
},
"support_data": {
"roles": {
"benefactor": true,
"partner": true,
"associationMember": false,
"promoter": false,
"volunteer": true
},
"benefactor": {
"campaignBenefactor": true,
"platformBenefactor": false
},
"partner": {
"npo": false,
"bussiness": true,
"other": false,
"otherText": "aaaaa"
},
"volunteer": {
"backend": false,
"frontend": true,
"marketing": false,
"designer": true,
"projectManager": false,
"devOps": true,
"financesAndAccounts": true,
"lawyer": false,
"qa": false
},
"associationMember": {
"isMember": true
},
"promoter": {
"mediaPartner": false,
"ambassador": false,
"other": true,
"otherText": "bbbbb"
}
},
"createdAt": "2021-04-07T12:57:09.42898025Z",
"updatedAt": "2021-04-07T12:57:09.42898025Z",
"deletedAt": null
}{
"statusCode": 400,
"error": "Person.email: non zero value required;Person.name: non zero value required;Person.phone: non zero value required",
"validation": [
{
"field": "Person.email",
"message": "Person.email: non zero value required",
"validator": "required",
"customMessage": false
},
{
"field": "Person.name",
"message": "Person.name: non zero value required",
"validator": "required",
"customMessage": false
},
{
"field": "Person.phone",
"message": "Person.phone: non zero value required",
"validator": "required",
"customMessage": false
}
]
}[
{
"id": "17222da9-b550-4e82-a6c6-88100bf54675",
"person": {
"email": "",
"name": "",
"phone": "",
"address": "",
"terms": false,
"newsletter": false
},
"support_data": {
"roles": {
"benefactor": false,
"partner": false,
"associationMember": false,
"promoter": false,
"volunteer": false
},
"benefactor": {
"campaignBenefactor": false,
"platformBenefactor": false
},
"partner": {
"npo": false,
"bussiness": false,
"other": false,
"otherText": ""
},
"volunteer": {
"backend": false,
"frontend": false,
"marketing": false,
"designer": false,
"projectManager": false,
"devOps": false,
"financesAndAccounts": false,
"lawyer": false,
"qa": false
},
"associationMember": {
"isMember": false
},
"promoter": {
"mediaPartner": false,
"ambassador": false,
"other": false,
"otherText": ""
}
},
"createdAt": "2021-04-07T09:16:28.026936Z",
"updatedAt": "2021-04-07T09:16:28.026936Z",
"deletedAt": null
}
]{
"id": "17222da9-b550-4e82-a6c6-88100bf54675",
"person": {
"email": "",
"name": "",
"phone": "",
"address": "",
"terms": false,
"newsletter": false
},
"support_data": {
"roles": {
"benefactor": false,
"partner": false,
"associationMember": false,
"promoter": false,
"volunteer": false
},
"benefactor": {
"campaignBenefactor": false,
"platformBenefactor": false
},
"partner": {
"npo": false,
"bussiness": false,
"other": false,
"otherText": ""
},
"volunteer": {
"backend": false,
"frontend": false,
"marketing": false,
"designer": false,
"projectManager": false,
"devOps": false,
"financesAndAccounts": false,
"lawyer": false,
"qa": false
},
"associationMember": {
"isMember": false
},
"promoter": {
"mediaPartner": false,
"ambassador": false,
"other": false,
"otherText": ""
}
},
"createdAt": "2021-04-07T09:16:28.026936Z",
"updatedAt": "2021-04-07T09:16:28.026936Z",
"deletedAt": null
}{
"error": "No support request found",
"status": 404
}{
"status": 200
}{
"status": 404
}import React, { useState } from 'react'
import { useTranslation } from 'next-i18next'
import Nav from 'components/layout/Nav'
import Layout from 'components/layout/Layout'
import SimpleForm from './SimpleForm'
import styles from './advanced.module.scss'export default () => <div>page</div>class Page extends React.Component {
render() {
return <div>page</div>
}
}export default function GenericForm() {}type AdvancedFormProps = React.PropsWithChildren({
title?: string
age?: number
})
export default function AdvancedForm({ title = 'Nice', children, age }: AdvancedFormProps) {
return (
<div title={title} data-age={age}>
{children}
</div>
)
}export default function RegisterPage() {
return <div>page</div>
}function RegisterPage() {
return <div>page</div>
}
Register.getInitialProps = async (ctx) => {
return { stars: 128 }
}
export default RegisterPageconst RegisterForm = () => <form>page</form>
export default function RegisterPage() {
return <RegisterForm />
}<Box component="nav" px={5} mt={2}>
<a>{t('nav.forgottenPassword')}</p>
</Box><Box component="nav" px={5} pb={12} mt={2} mb={4} lineHeight={2} letterSpacing={none} fontSize={20}>
<Box component="span" px={5} pb={12} mt={2} mb={4} lineHeight={2} letterSpacing={none} fontSize={17}>
<a>{t('nav.forgottenPassword')}</p>
</Box>
<Box component="span" px={5} pb={12} mt={2} mb={4} lineHeight={2} letterSpacing={none} fontSize={13}>
<a>{t('nav.forgottenPassword')}</p>
</Box>
</Box>const useStyles = makeStyles((theme) =>
createStyles({
pageTitle: {
display: 'flex',
flexDirection: 'column',
alignItems: 'center',
padding: theme.spacing(4),
margin: theme.spacing(5, 3, 4),
color: theme.palette.secondary.main,
backgroundColor: theme.palette.primary.main,
'&:hover': {
color: theme.palette.secondary.dark,
},
},
// ...
}),
)
export default function SomeBox() {
const classes = useStyles()
return (
<Box className={classes.pageTitle}>
<p>{t('nav.forgottenPassword')}</p>
</Box>
)
}@import 'styles/variables';
.page {
color: $text-color;
.nav {
background-color: $nav-color;
a {
text-decoration: none;
text-transform: uppercase;
}
}
}import styles from './about.module.scss'
<Box className={styles.page}>
<p>{t('nav.forgottenPassword')}</p>
</Box>@import 'styles/variables';
a {
text-decoration: none;
}const RegisterPage = () => <form>page</form>
export default RegisterPage